Papers
Evolutionary Computation in the Era of Large Language Model: Survey and Roadmap
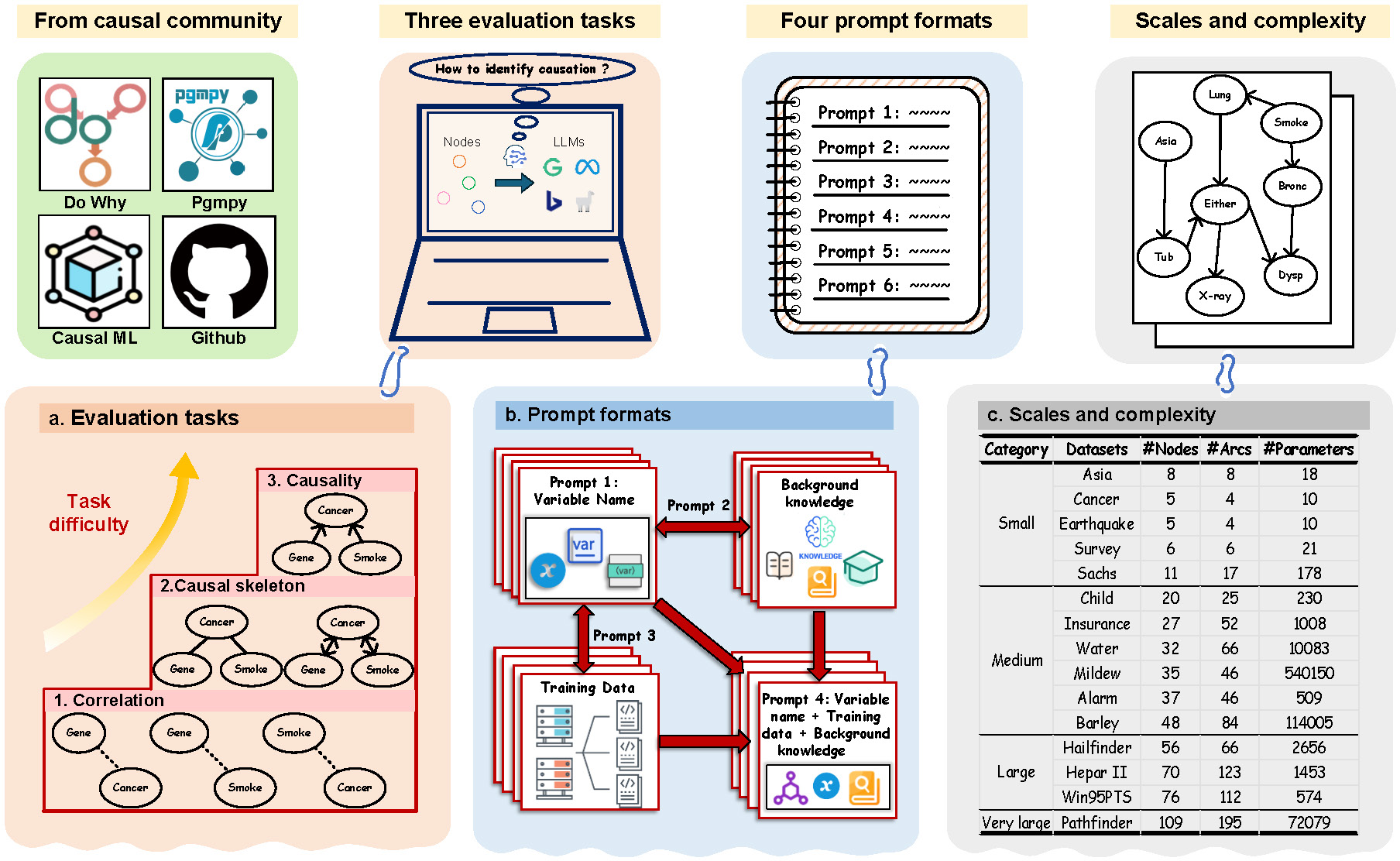
CausalBench: A Comprehensive Benchmark for Causal Learning Capability of Large Language Models
- Diverse scales of datasets from the causal learning community.
This work is an extension of the causal learning research community’s efforts, designed to offer a robust evaluation framework. It incorporates 15 commonly used real-world causal learning datasets of diverse scales, enabling rigorous and quantitative measurement of LLMs' causal learning capacities with extensive evaluation results in the causal research community as a reference.
- Evaluation tasks of varying depths and difficulties
This work offers three tasks of different difficulties, i.e. correlation, causal skeleton, and causality identification respectively, to holistically assess the causal learning capabilities of existing LLMs. Additionally, we have provided an example on causal structures similar to a particular prompt technique, which identifies the long cause-effect chain to evaluate causal learning abilities on multi-step reasoning like the popular Chain-of-Thought (CoT) prompt technique.
- Diverse prompts with rich information
This work offers four distinct prompt formats, encompassing variable name and its combinations with background knowledge and training data respectively and the combination of the three. With these diverse prompts, This work can well assess LLMs' causal learning capacities through looking into their abilities to utilize prior information and comprehend long-text in understanding causal relations.
- Demonstration of the upper limit of LLMs’ causal learning capability across various
scales and complexities
This work evaluates causal relations of varying scales and complexities. This work covers causal learning datasets with scales ranging from 5 to 109 nodes, far exceeding what current evaluation works have explored. Meanwhile, it evaluates various types of causal structures and discusses different densities in causal learning networks.